Train and evaluate models
This notebooks shows how to train, predict and cluster models. Alternatively to executing each step here, the CLI can be used for training models:
cd CAMPA_DIR/params
campa train all --config example_experiment_params.py
For evaluation or comparison only, use
cd CAMPA_DIR/params
campa train compare --experiment-dir test
Before running this tutorial, make sure you create the NNDataset with the create NNDataset tutorial. The models trained here will be saved in EXPERIMENT_DIR/test, with the EXPERIMENT_DIR being the custom experiment path set up in campa_config.
[1]:
from pathlib import Path
import os
from campa.tl import (
Cluster,
Estimator,
Predictor,
Experiment,
ModelComparator,
run_experiments,
)
from campa.data import MPPData
from campa.utils import init_logging
from campa.constants import campa_config
# init logging with level INFO=20, WARNING=30
init_logging(level=30)
# read correct campa_config -- created with setup.ipynb
CAMPA_DIR = Path.cwd()
campa_config.config_fname = CAMPA_DIR / "params/campa.ini"
print(campa_config)
2022-11-25 11:07:57.922828: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F AVX512_VNNI FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2022-11-25 11:07:59.660494: I tensorflow/core/util/util.cc:169] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
2022-11-25 11:07:59.960552: E tensorflow/stream_executor/cuda/cuda_blas.cc:2981] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
Reading config from /home/icb/hannah.spitzer/projects/pelkmans/software_new/campa_notebooks_test/params/campa.ini
CAMPAConfig (fname: /home/icb/hannah.spitzer/projects/pelkmans/software_new/campa_notebooks_test/params/campa.ini)
EXPERIMENT_DIR: /home/icb/hannah.spitzer/projects/pelkmans/software_new/campa_notebooks_test/example_experiments
BASE_DATA_DIR: /home/icb/hannah.spitzer/projects/pelkmans/software_new/campa_notebooks_test/example_data
CO_OCC_CHUNK_SIZE: 10000000.0
data_config/exampledata: /home/icb/hannah.spitzer/projects/pelkmans/software_new/campa_notebooks_test/params/ExampleData_constants.py
Experiment class handles config files
For training and evaluating models, an experiment_params.py file is used. This file contains several model/experiment parameters for easy training of several models at the same time. The parameter dictionaries contain several sections:
experiment (where to save experiment)
data (which dataset to use for training)
model (model class definition)
training (training hyper-parameters)
evaluation (evaluation on val/test split)
cluster (clustering on val/test split)
For more information on the structure of the experiment parameter dictionary, see the documentation of Experiment. The Experiment class is initialised from a parameter dictionary for one specific experiment and is passed to specific classes for training (Estimator), evaluation (Predictor), and clustering (Cluster).
Here, we are going to be using an example experiment config that creates three models: - condVAE: a cVAE model trained on the example dataset created in the NNDataset tutorial, using perturbation (unperturbed or Meayamycin) and cell cycle as conditions - VAE: a VAE model trained on the example dataset created in the NNDataset tutorial, -
MPPleiden: a non-trainable model that is used to create a direct pixel clustering, to compare with the cVAE latent space clustering.
First, we create the Experiments from the example config file:
[2]:
# get Experiments from config
exps = Experiment.get_experiments_from_config("params/example_experiment_params.py")
Experiments are saved in EXPERIMENT_DIR/<experiment_dir>/<experiment_name>, where EXPERIMENT_DIR is the directory set up in campa_config, and <experiment_dir> and <experiment_name> are defined in the experiment config. The experiment config can be accessed with Experiment.config and is stored as config.json in the experiment folder.
[3]:
exp = exps[0]
print("Experiment name:", exp.name)
print("Experiment is stored in:", exp.full_path)
print("Experiment config:", exp.config)
Experiment name: VAE
Experiment is stored in: /home/icb/hannah.spitzer/projects/pelkmans/software_new/campa_notebooks_test/example_experiments/test/VAE
Experiment config: {'experiment': {'dir': 'test', 'name': 'VAE', 'save_config': True}, 'data': {'data_config': 'ExampleData', 'dataset_name': '184A1_test_dataset', 'output_channels': None}, 'model': {'model_cls': <ModelEnum.VAEModel: 'VAEModel'>, 'model_kwargs': {'num_neighbors': 3, 'num_channels': 34, 'num_output_channels': 34, 'latent_dim': 16, 'encoder_conv_layers': [32], 'encoder_conv_kernel_size': [1], 'encoder_fc_layers': [32, 16], 'decoder_fc_layers': []}, 'init_with_weights': False}, 'training': {'learning_rate': 0.001, 'epochs': 10, 'batch_size': 128, 'loss': {'decoder': <LossEnum.SIGMA_MSE: 'sigma_vae_mse'>, 'latent': <LossEnum.KL: 'kl_divergence'>}, 'loss_weights': {'decoder': 1}, 'loss_warmup_to_epoch': {}, 'metrics': {'decoder': <LossEnum.MSE_metric: 'mean_squared_error_metric'>, 'latent': <LossEnum.KL: 'kl_divergence'>}, 'save_model_weights': True, 'save_history': True, 'overwrite_history': True}, 'evaluation': {'split': 'val', 'predict_reps': ['latent', 'decoder'], 'img_ids': 2, 'predict_imgs': True, 'predict_cluster_imgs': True}, 'cluster': {'predict_cluster_imgs': True, 'cluster_name': 'clustering', 'cluster_rep': 'latent', 'cluster_method': 'leiden', 'leiden_resolution': 0.2, 'subsample': None, 'subsample_kwargs': {}, 'som_kwargs': {}, 'umap': True}}
Running experiments with the high-level api
The high-level api contains a run_experiments() function that wraps training, evaluation, clustering and comparison of models in one call.
[4]:
run_experiments(exps, mode="trainval")
Running experiment for ['VAE', 'CondVAE_pert-CC', 'MPPleiden'] with mode trainval
Training model for VAE
2022-11-25 11:08:48.091386: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F AVX512_VNNI FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2022-11-25 11:08:55.819611: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1616] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 30975 MB memory: -> device: 0, name: Tesla V100S-PCIE-32GB, pci bus id: 0000:37:00.0, compute capability: 7.0
Epoch 1/10
2022-11-25 11:09:04.047735: I tensorflow/stream_executor/cuda/cuda_dnn.cc:384] Loaded cuDNN version 8202
394/394 [==============================] - 14s 22ms/step - loss: -54.6142 - decoder_loss: -60.4548 - latent_loss: 5.8410 - decoder_mean_squared_error: 0.1186 - latent_kl_loss: 5.8438 - val_loss: -1461.2408 - val_decoder_loss: -1469.6049 - val_latent_loss: 8.3641 - val_decoder_mean_squared_error: 0.0308 - val_latent_kl_loss: 8.3667
Epoch 2/10
394/394 [==============================] - 8s 17ms/step - loss: -1727.2487 - decoder_loss: -1735.4847 - latent_loss: 8.2352 - decoder_mean_squared_error: 0.0265 - latent_kl_loss: 8.2305 - val_loss: -1775.4342 - val_decoder_loss: -1784.1416 - val_latent_loss: 8.7079 - val_decoder_mean_squared_error: 0.0268 - val_latent_kl_loss: 8.7105
Epoch 3/10
394/394 [==============================] - 8s 17ms/step - loss: -1899.6907 - decoder_loss: -1907.9985 - latent_loss: 8.3079 - decoder_mean_squared_error: 0.0245 - latent_kl_loss: 8.3114 - val_loss: -1812.8528 - val_decoder_loss: -1821.5256 - val_latent_loss: 8.6733 - val_decoder_mean_squared_error: 0.0263 - val_latent_kl_loss: 8.6758
Epoch 4/10
394/394 [==============================] - 8s 17ms/step - loss: -1983.5101 - decoder_loss: -1991.8229 - latent_loss: 8.3129 - decoder_mean_squared_error: 0.0235 - latent_kl_loss: 8.3082 - val_loss: -1779.9838 - val_decoder_loss: -1788.4822 - val_latent_loss: 8.4980 - val_decoder_mean_squared_error: 0.0267 - val_latent_kl_loss: 8.5003
Epoch 5/10
394/394 [==============================] - 8s 17ms/step - loss: -2030.0353 - decoder_loss: -2038.2104 - latent_loss: 8.1763 - decoder_mean_squared_error: 0.0231 - latent_kl_loss: 8.1751 - val_loss: -1871.1638 - val_decoder_loss: -1879.5934 - val_latent_loss: 8.4300 - val_decoder_mean_squared_error: 0.0257 - val_latent_kl_loss: 8.4323
Epoch 6/10
394/394 [==============================] - 8s 17ms/step - loss: -2055.1208 - decoder_loss: -2063.1494 - latent_loss: 8.0277 - decoder_mean_squared_error: 0.0228 - latent_kl_loss: 8.0278 - val_loss: -1832.2227 - val_decoder_loss: -1840.4135 - val_latent_loss: 8.1906 - val_decoder_mean_squared_error: 0.0262 - val_latent_kl_loss: 8.1927
Epoch 7/10
394/394 [==============================] - 8s 17ms/step - loss: -2072.0718 - decoder_loss: -2079.9519 - latent_loss: 7.8805 - decoder_mean_squared_error: 0.0226 - latent_kl_loss: 7.8791 - val_loss: -1896.3907 - val_decoder_loss: -1904.4248 - val_latent_loss: 8.0340 - val_decoder_mean_squared_error: 0.0254 - val_latent_kl_loss: 8.0361
Epoch 8/10
394/394 [==============================] - 8s 17ms/step - loss: -2082.7478 - decoder_loss: -2090.5005 - latent_loss: 7.7527 - decoder_mean_squared_error: 0.0225 - latent_kl_loss: 7.7545 - val_loss: -1867.6969 - val_decoder_loss: -1875.5791 - val_latent_loss: 7.8826 - val_decoder_mean_squared_error: 0.0258 - val_latent_kl_loss: 7.8845
Epoch 9/10
394/394 [==============================] - 8s 17ms/step - loss: -2091.8447 - decoder_loss: -2099.4902 - latent_loss: 7.6441 - decoder_mean_squared_error: 0.0224 - latent_kl_loss: 7.6453 - val_loss: -1876.2723 - val_decoder_loss: -1884.0425 - val_latent_loss: 7.7702 - val_decoder_mean_squared_error: 0.0257 - val_latent_kl_loss: 7.7720
Epoch 10/10
394/394 [==============================] - 8s 17ms/step - loss: -2095.2839 - decoder_loss: -2102.7478 - latent_loss: 7.4648 - decoder_mean_squared_error: 0.0224 - latent_kl_loss: 7.4653 - val_loss: -1898.8521 - val_decoder_loss: -1906.3774 - val_latent_loss: 7.5262 - val_decoder_mean_squared_error: 0.0254 - val_latent_kl_loss: 7.5278
Evaluating model for VAE
97/97 [==============================] - 0s 1ms/step
97/97 [==============================] - 0s 1ms/step
319/319 [==============================] - 0s 1ms/step
319/319 [==============================] - 0s 1ms/step
Clustering results for VAE
Cannot read with memmap: /home/icb/hannah.spitzer/projects/pelkmans/software_new/campa_notebooks_test/example_experiments/test/VAE/results_epoch010/val/clustering.npy
/home/icb/hannah.spitzer/miniconda3/envs/campa/lib/python3.9/site-packages/tqdm/auto.py:22: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
WARNING:MPPData:Saving partial keys of mpp data without a base_data_dir to enable correct loading
WARNING:MPPData:Saving partial keys of mpp data without a base_data_dir to enable correct loading
Training model for CondVAE_pert-CC
Epoch 1/10
394/394 [==============================] - 11s 21ms/step - loss: -96.7190 - decoder_loss: -108.3478 - latent_loss: 11.6285 - decoder_mean_squared_error: 0.0962 - latent_kl_loss: 11.6341 - val_loss: -1121.3718 - val_decoder_loss: -1135.7074 - val_latent_loss: 14.3359 - val_decoder_mean_squared_error: 0.0355 - val_latent_kl_loss: 14.3381
Epoch 2/10
394/394 [==============================] - 9s 20ms/step - loss: -1598.8888 - decoder_loss: -1611.3558 - latent_loss: 12.4673 - decoder_mean_squared_error: 0.0281 - latent_kl_loss: 12.4833 - val_loss: -1597.4363 - val_decoder_loss: -1609.7793 - val_latent_loss: 12.3429 - val_decoder_mean_squared_error: 0.0285 - val_latent_kl_loss: 12.3442
Epoch 3/10
394/394 [==============================] - 9s 20ms/step - loss: -1869.5409 - decoder_loss: -1880.0975 - latent_loss: 10.5565 - decoder_mean_squared_error: 0.0248 - latent_kl_loss: 10.5569 - val_loss: -1745.0593 - val_decoder_loss: -1755.3724 - val_latent_loss: 10.3129 - val_decoder_mean_squared_error: 0.0267 - val_latent_kl_loss: 10.3140
Epoch 4/10
394/394 [==============================] - 9s 20ms/step - loss: -2038.8110 - decoder_loss: -2047.9432 - latent_loss: 9.1308 - decoder_mean_squared_error: 0.0230 - latent_kl_loss: 9.1282 - val_loss: -1810.5372 - val_decoder_loss: -1819.9731 - val_latent_loss: 9.4353 - val_decoder_mean_squared_error: 0.0260 - val_latent_kl_loss: 9.4362
Epoch 5/10
394/394 [==============================] - 9s 20ms/step - loss: -2131.1963 - decoder_loss: -2139.6418 - latent_loss: 8.4446 - decoder_mean_squared_error: 0.0220 - latent_kl_loss: 8.4430 - val_loss: -1829.8097 - val_decoder_loss: -1838.4362 - val_latent_loss: 8.6265 - val_decoder_mean_squared_error: 0.0259 - val_latent_kl_loss: 8.6272
Epoch 6/10
394/394 [==============================] - 9s 20ms/step - loss: -2179.8435 - decoder_loss: -2187.7412 - latent_loss: 7.8981 - decoder_mean_squared_error: 0.0215 - latent_kl_loss: 7.8999 - val_loss: -1886.1505 - val_decoder_loss: -1894.4392 - val_latent_loss: 8.2890 - val_decoder_mean_squared_error: 0.0253 - val_latent_kl_loss: 8.2896
Epoch 7/10
394/394 [==============================] - 9s 20ms/step - loss: -2213.2449 - decoder_loss: -2220.8142 - latent_loss: 7.5693 - decoder_mean_squared_error: 0.0212 - latent_kl_loss: 7.5680 - val_loss: -1909.7399 - val_decoder_loss: -1917.5172 - val_latent_loss: 7.7776 - val_decoder_mean_squared_error: 0.0251 - val_latent_kl_loss: 7.7781
Epoch 8/10
394/394 [==============================] - 9s 20ms/step - loss: -2238.7202 - decoder_loss: -2246.0688 - latent_loss: 7.3495 - decoder_mean_squared_error: 0.0210 - latent_kl_loss: 7.3519 - val_loss: -1905.4167 - val_decoder_loss: -1913.1265 - val_latent_loss: 7.7099 - val_decoder_mean_squared_error: 0.0251 - val_latent_kl_loss: 7.7103
Epoch 9/10
394/394 [==============================] - 9s 20ms/step - loss: -2288.4106 - decoder_loss: -2295.5720 - latent_loss: 7.1623 - decoder_mean_squared_error: 0.0205 - latent_kl_loss: 7.1604 - val_loss: -2012.9708 - val_decoder_loss: -2020.5276 - val_latent_loss: 7.5560 - val_decoder_mean_squared_error: 0.0239 - val_latent_kl_loss: 7.5564
Epoch 10/10
394/394 [==============================] - 9s 20ms/step - loss: -2373.5266 - decoder_loss: -2380.6680 - latent_loss: 7.1418 - decoder_mean_squared_error: 0.0197 - latent_kl_loss: 7.1406 - val_loss: -2084.1760 - val_decoder_loss: -2091.7673 - val_latent_loss: 7.5919 - val_decoder_mean_squared_error: 0.0232 - val_latent_kl_loss: 7.5923
Evaluating model for CondVAE_pert-CC
97/97 [==============================] - 0s 1ms/step
97/97 [==============================] - 0s 1ms/step
319/319 [==============================] - 0s 1ms/step
319/319 [==============================] - 0s 1ms/step
Clustering results for CondVAE_pert-CC
WARNING:MPPData:Saving partial keys of mpp data without a base_data_dir to enable correct loading
WARNING:MPPData:Saving partial keys of mpp data without a base_data_dir to enable correct loading
Clustering results for MPPleiden
WARNING:MPPData:Saving partial keys of mpp data without a base_data_dir to enable correct loading
WARNING:MPPData:Saving partial keys of mpp data without a base_data_dir to enable correct loading
This should have created the three trained experiments in EXPERIMENT_DIR/test (test is the <experiment_dir> defined in the config):
[5]:
os.listdir(os.path.join(campa_config.EXPERIMENT_DIR, "test"))
[5]:
['CondVAE_pert-CC', 'VAE', 'MPPleiden']
Running experiments with Estimator and Predictor
Now, we will be using the cVAE experiment to show how to use the Estimator and Predictor classes. Note that if you ran the command above, this model is already trained, and the below commands will re-train it.
Neural network training with Estimator
The Estimator class handles model setup, training, and prediction. It is instantiated from an Experiment.
[6]:
exp = exps[1]
print("Experiment name:", exp.name)
print("Experiment is stored in:", exp.full_path)
Experiment name: CondVAE_pert-CC
Experiment is stored in: /home/icb/hannah.spitzer/projects/pelkmans/software_new/campa_notebooks_test/example_experiments/test/CondVAE_pert-CC
[7]:
est = Estimator(exp)
The Estimator.train_model() function is used to train the experiment.
[8]:
est.train_model()
Epoch 1/10
394/394 [==============================] - 10s 21ms/step - loss: -2423.9329 - decoder_loss: -2431.0073 - latent_loss: 7.0749 - decoder_mean_squared_error: 0.0192 - latent_kl_loss: 7.0753 - val_loss: -2109.7830 - val_decoder_loss: -2117.1072 - val_latent_loss: 7.3246 - val_decoder_mean_squared_error: 0.0231 - val_latent_kl_loss: 7.3250
Epoch 2/10
394/394 [==============================] - 9s 20ms/step - loss: -2481.6553 - decoder_loss: -2488.6077 - latent_loss: 6.9536 - decoder_mean_squared_error: 0.0187 - latent_kl_loss: 6.9541 - val_loss: -2157.7593 - val_decoder_loss: -2165.0781 - val_latent_loss: 7.3189 - val_decoder_mean_squared_error: 0.0226 - val_latent_kl_loss: 7.3193
Epoch 3/10
394/394 [==============================] - 9s 21ms/step - loss: -2531.1716 - decoder_loss: -2538.0715 - latent_loss: 6.9019 - decoder_mean_squared_error: 0.0183 - latent_kl_loss: 6.9030 - val_loss: -2232.9197 - val_decoder_loss: -2240.2471 - val_latent_loss: 7.3282 - val_decoder_mean_squared_error: 0.0217 - val_latent_kl_loss: 7.3285
Epoch 4/10
394/394 [==============================] - 9s 20ms/step - loss: -2570.6665 - decoder_loss: -2577.5518 - latent_loss: 6.8846 - decoder_mean_squared_error: 0.0179 - latent_kl_loss: 6.8844 - val_loss: -2267.1956 - val_decoder_loss: -2274.5400 - val_latent_loss: 7.3443 - val_decoder_mean_squared_error: 0.0213 - val_latent_kl_loss: 7.3445
Epoch 5/10
394/394 [==============================] - 9s 20ms/step - loss: -2596.6277 - decoder_loss: -2603.4556 - latent_loss: 6.8281 - decoder_mean_squared_error: 0.0177 - latent_kl_loss: 6.8282 - val_loss: -2311.4065 - val_decoder_loss: -2318.5420 - val_latent_loss: 7.1355 - val_decoder_mean_squared_error: 0.0209 - val_latent_kl_loss: 7.1357
Epoch 6/10
394/394 [==============================] - 9s 20ms/step - loss: -2613.1116 - decoder_loss: -2619.9062 - latent_loss: 6.7942 - decoder_mean_squared_error: 0.0176 - latent_kl_loss: 6.7924 - val_loss: -2265.0884 - val_decoder_loss: -2272.2742 - val_latent_loss: 7.1861 - val_decoder_mean_squared_error: 0.0213 - val_latent_kl_loss: 7.1862
Epoch 7/10
394/394 [==============================] - 9s 20ms/step - loss: -2622.1897 - decoder_loss: -2628.9617 - latent_loss: 6.7705 - decoder_mean_squared_error: 0.0175 - latent_kl_loss: 6.7707 - val_loss: -2274.3088 - val_decoder_loss: -2281.4370 - val_latent_loss: 7.1281 - val_decoder_mean_squared_error: 0.0212 - val_latent_kl_loss: 7.1281
Epoch 8/10
394/394 [==============================] - 9s 20ms/step - loss: -2625.8840 - decoder_loss: -2632.5740 - latent_loss: 6.6894 - decoder_mean_squared_error: 0.0175 - latent_kl_loss: 6.6884 - val_loss: -2317.0896 - val_decoder_loss: -2324.1270 - val_latent_loss: 7.0367 - val_decoder_mean_squared_error: 0.0208 - val_latent_kl_loss: 7.0367
Epoch 9/10
394/394 [==============================] - 9s 20ms/step - loss: -2630.3965 - decoder_loss: -2637.0344 - latent_loss: 6.6381 - decoder_mean_squared_error: 0.0175 - latent_kl_loss: 6.6368 - val_loss: -2297.4724 - val_decoder_loss: -2304.4858 - val_latent_loss: 7.0141 - val_decoder_mean_squared_error: 0.0210 - val_latent_kl_loss: 7.0141
Epoch 10/10
394/394 [==============================] - 9s 20ms/step - loss: -2634.0779 - decoder_loss: -2640.6655 - latent_loss: 6.5884 - decoder_mean_squared_error: 0.0174 - latent_kl_loss: 6.5918 - val_loss: -2286.9790 - val_decoder_loss: -2294.0789 - val_latent_loss: 7.1011 - val_decoder_mean_squared_error: 0.0210 - val_latent_kl_loss: 7.1011
[8]:
| loss | decoder_loss | latent_loss | decoder_mean_squared_error | latent_kl_loss | val_loss | val_decoder_loss | val_latent_loss | val_decoder_mean_squared_error | val_latent_kl_loss | |
|---|---|---|---|---|---|---|---|---|---|---|
| epoch | ||||||||||
| 0 | -2423.932861 | -2431.007324 | 7.074893 | 0.019210 | 7.075301 | -2109.782959 | -2117.107178 | 7.324591 | 0.023058 | 7.324974 |
| 1 | -2481.655273 | -2488.607666 | 6.953554 | 0.018704 | 6.954084 | -2157.759277 | -2165.078125 | 7.318946 | 0.022575 | 7.319310 |
| 2 | -2531.171631 | -2538.071533 | 6.901866 | 0.018289 | 6.902996 | -2232.919678 | -2240.247070 | 7.328206 | 0.021735 | 7.328503 |
| 3 | -2570.666504 | -2577.551758 | 6.884612 | 0.017950 | 6.884366 | -2267.195557 | -2274.540039 | 7.344334 | 0.021303 | 7.344531 |
| 4 | -2596.627686 | -2603.455566 | 6.828085 | 0.017743 | 6.828167 | -2311.406494 | -2318.541992 | 7.135535 | 0.020870 | 7.135660 |
| 5 | -2613.111572 | -2619.906250 | 6.794180 | 0.017608 | 6.792426 | -2265.088379 | -2272.274170 | 7.186080 | 0.021294 | 7.186206 |
| 6 | -2622.189697 | -2628.961670 | 6.770476 | 0.017539 | 6.770661 | -2274.308838 | -2281.437012 | 7.128055 | 0.021195 | 7.128136 |
| 7 | -2625.884033 | -2632.573975 | 6.689381 | 0.017503 | 6.688420 | -2317.089600 | -2324.126953 | 7.036691 | 0.020774 | 7.036706 |
| 8 | -2630.396484 | -2637.034424 | 6.638138 | 0.017471 | 6.636763 | -2297.472412 | -2304.485840 | 7.014103 | 0.020958 | 7.014116 |
| 9 | -2634.077881 | -2640.665527 | 6.588428 | 0.017442 | 6.591764 | -2286.979004 | -2294.078857 | 7.101054 | 0.021028 | 7.101066 |
This saves the weights of the best model in the experiment directory.
[9]:
print(os.listdir(exp.full_path))
['checkpoint', 'results_epoch010', 'weights_epoch010.index', 'config.json', 'weights_epoch010.data-00000-of-00001', 'history.csv']
Predict val split and images with Predictor
The Predictor class can evaluate and predict new data from trained models. It is instantiated with an Experiment.
[10]:
pred = Predictor(exp)
pred.evaluate_model()
97/97 [==============================] - 0s 1ms/step
97/97 [==============================] - 0s 2ms/step
319/319 [==============================] - 0s 1ms/step
319/319 [==============================] - 0s 1ms/step
This function evaluates the model on the val and val_imgs split, and stores the results in a results folder inside the experiment directory.
[11]:
results_folder = os.path.join(pred.exp.full_path, f"results_epoch{pred.est.epoch:03d}")
print("Results folder", results_folder)
print(os.listdir(results_folder))
Results folder /home/icb/hannah.spitzer/projects/pelkmans/software_new/campa_notebooks_test/example_experiments/test/CondVAE_pert-CC/results_epoch010
['val', 'val_imgs']
The results are stored as `MPPData <../classes/campa.data.MPPData.rst>`__ objects. Note that it is important to define data_config when initialising the `MPPData <../classes/campa.data.MPPData.rst>`__, to ensure that the data is found.
[12]:
print(MPPData.from_data_dir(os.path.join(results_folder, "val"), data_config="ExampleData"))
MPPData for ExampleData (12340 mpps with shape (3, 3, 34) from 8 objects). Data keys: ['obj_ids', 'x', 'y', 'mpp', 'conditions', 'labels', 'latent'].
Cluster resulting latent space with Cluster
To get a quick overview of the generated latent space and the clustering of the latent space, we can use the Cluster class to cluster the evaluation split of the data. To generate the final clustering utilising the entire dataset, have a look at the clustering tutorial.
[13]:
cl = Cluster.from_exp_split(exps[1])
Cannot read with memmap: /home/icb/hannah.spitzer/projects/pelkmans/software_new/campa_notebooks_test/example_experiments/test/CondVAE_pert-CC/results_epoch010/val/clustering.npy
Cluster the val split of the dataset. You can change the resolution of the clustering by setting the config["leiden_resolution"] parameter.
This will create npy files containing the clusters of every data point in the validation split in the experiment results folder
[14]:
print(cl.config["leiden_resolution"])
cl.create_clustering()
0.2
WARNING:MPPData:Saving partial keys of mpp data without a base_data_dir to enable correct loading
We can again load the evaluated val split using MPPData, this time including the clustering.
[15]:
mpp_data = MPPData.from_data_dir(os.path.join(results_folder, "val"), data_config="ExampleData", keys=["clustering"])
print("clustering:", mpp_data.data("clustering"))
Cannot read with memmap: /home/icb/hannah.spitzer/projects/pelkmans/software_new/campa_notebooks_test/example_experiments/test/CondVAE_pert-CC/results_epoch010/val/clustering.npy
clustering: ['0' '0' '2' ... '0' '1' '2']
Using this clustering, we can predict the clusters of the val_imgs split:
[16]:
# predict cluster images
_ = cl.predict_cluster_imgs(exps[1])
WARNING:MPPData:Saving partial keys of mpp data without a base_data_dir to enable correct loading
Plot results using ModelComparator
The ModelComparator class is a convenience class to allow quick comparison between different models. Below, we will compare the condVAE, VAE and MPPleiden experiments that we just trained.
Note that due to the stochastic nature of neural network training (e.g. due to different random initialisations), your outputs could look a bit different to the outputs in the documentation. You should be able to see the same trends though.
[17]:
# get saved experiments from dir
exps = Experiment.get_experiments_from_dir("test")
comp = ModelComparator(exps)
Cannot read with memmap: /home/icb/hannah.spitzer/projects/pelkmans/software_new/campa_notebooks_test/example_experiments/test/CondVAE_pert-CC/results_epoch010/val/clustering.npy
Cannot read with memmap: /home/icb/hannah.spitzer/projects/pelkmans/software_new/campa_notebooks_test/example_experiments/test/CondVAE_pert-CC/results_epoch010/val_imgs/clustering.npy
Cannot read with memmap: /home/icb/hannah.spitzer/projects/pelkmans/software_new/campa_notebooks_test/example_experiments/test/VAE/results_epoch010/val/clustering.npy
Cannot read with memmap: /home/icb/hannah.spitzer/projects/pelkmans/software_new/campa_notebooks_test/example_experiments/test/VAE/results_epoch010/val_imgs/clustering.npy
Cannot read with memmap: /home/icb/hannah.spitzer/projects/pelkmans/software_new/campa_notebooks_test/example_experiments/test/MPPleiden/results_epoch000/val/clustering.npy
Cannot read with memmap: /home/icb/hannah.spitzer/projects/pelkmans/software_new/campa_notebooks_test/example_experiments/test/MPPleiden/results_epoch000/val_imgs/clustering.npy
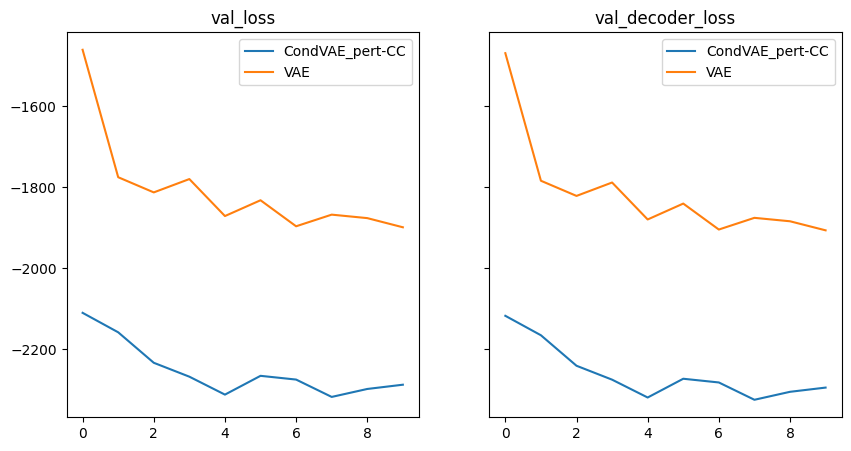
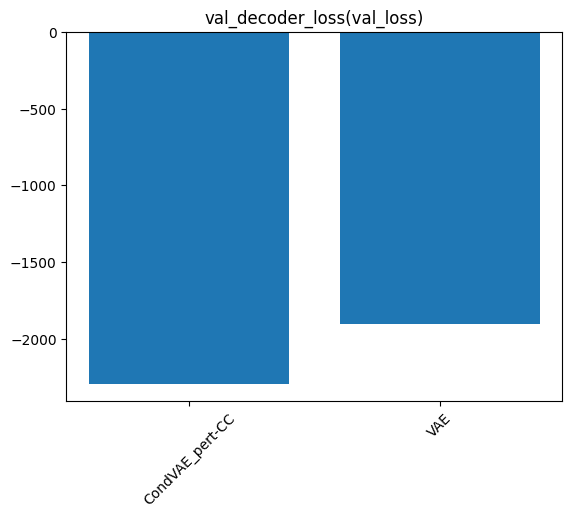
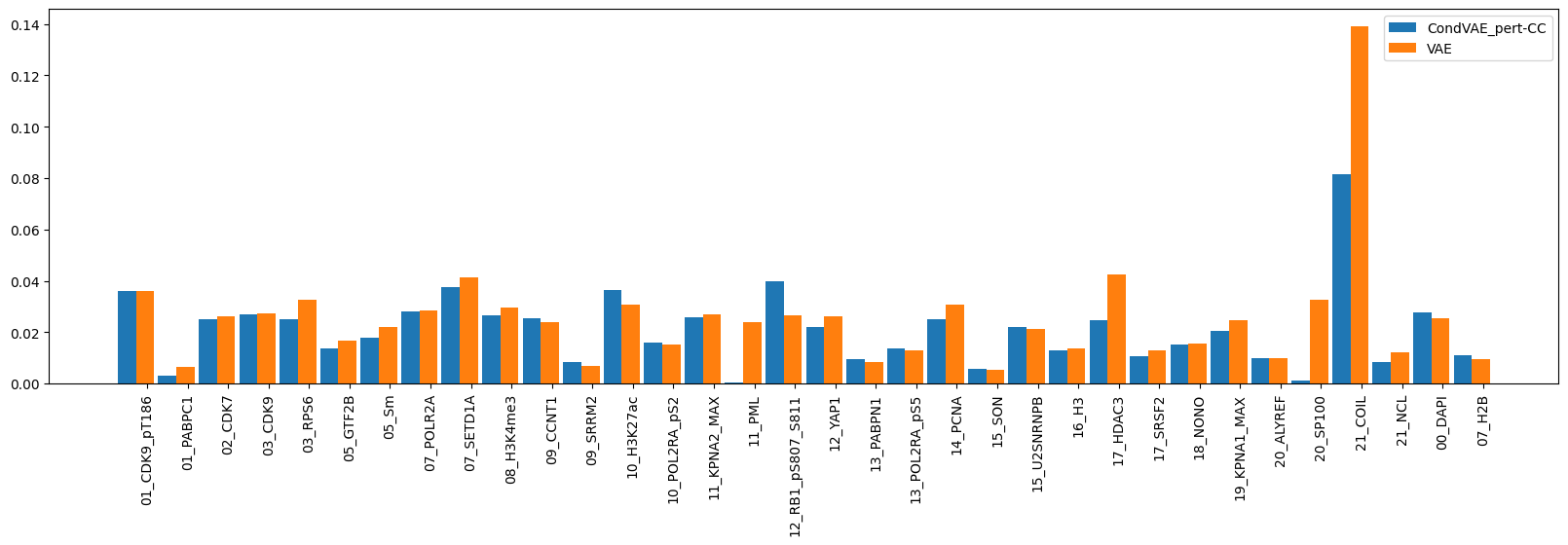
The loss and MSE summary plots show how the VAE and cVAE model perform with respect to reconstructing the input. Both models seem to be trained well, as indicated by the asymptotic loss curves
[18]:
comp.plot_history(values=["val_loss", "val_decoder_loss"])
comp.plot_final_score(score="val_decoder_loss", fallback_score="val_loss", save_prefix="decoder_loss_")
comp.plot_per_channel_mse()
The two example images show that both models can predict the original inputs well
[19]:
comp.plot_predicted_images(
img_ids=[
0,
1,
],
img_size=225,
)


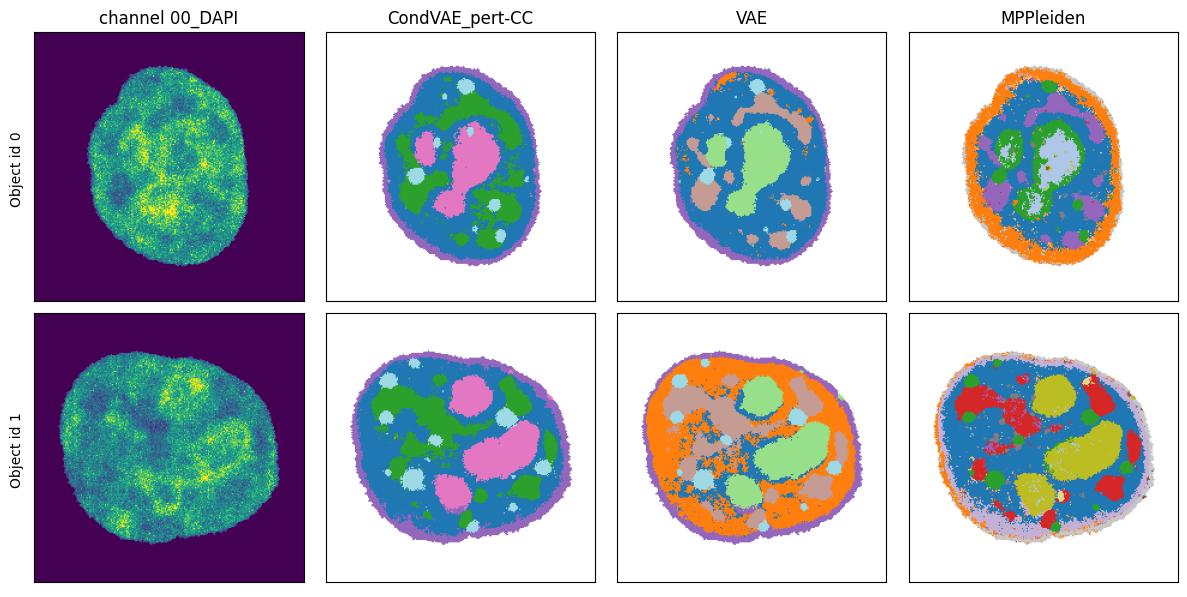
The example leiden clustering (here with resolution 0.2 as set in the experiment_params.py) shows some differences between the models. Even on these two example cells, the MPPleiden experiment (direct pixel clustering) seems to be less consistent across the cells. The condVAE clustering has distinct clusters for the periphery of some of the detected clusters. This is due to the training with a small local neighbourhood and the very limited data size in this toy example (only 10 cells
from each perturbation). To remove this effect and train without a local neighbourhood, set num_neighbors in the model definition in the experiment_params and in the dataset definition in the data_params to 1.
[20]:
comp.plot_cluster_images(
img_ids=[
0,
1,
],
img_size=225,
img_channel="00_DAPI",
)
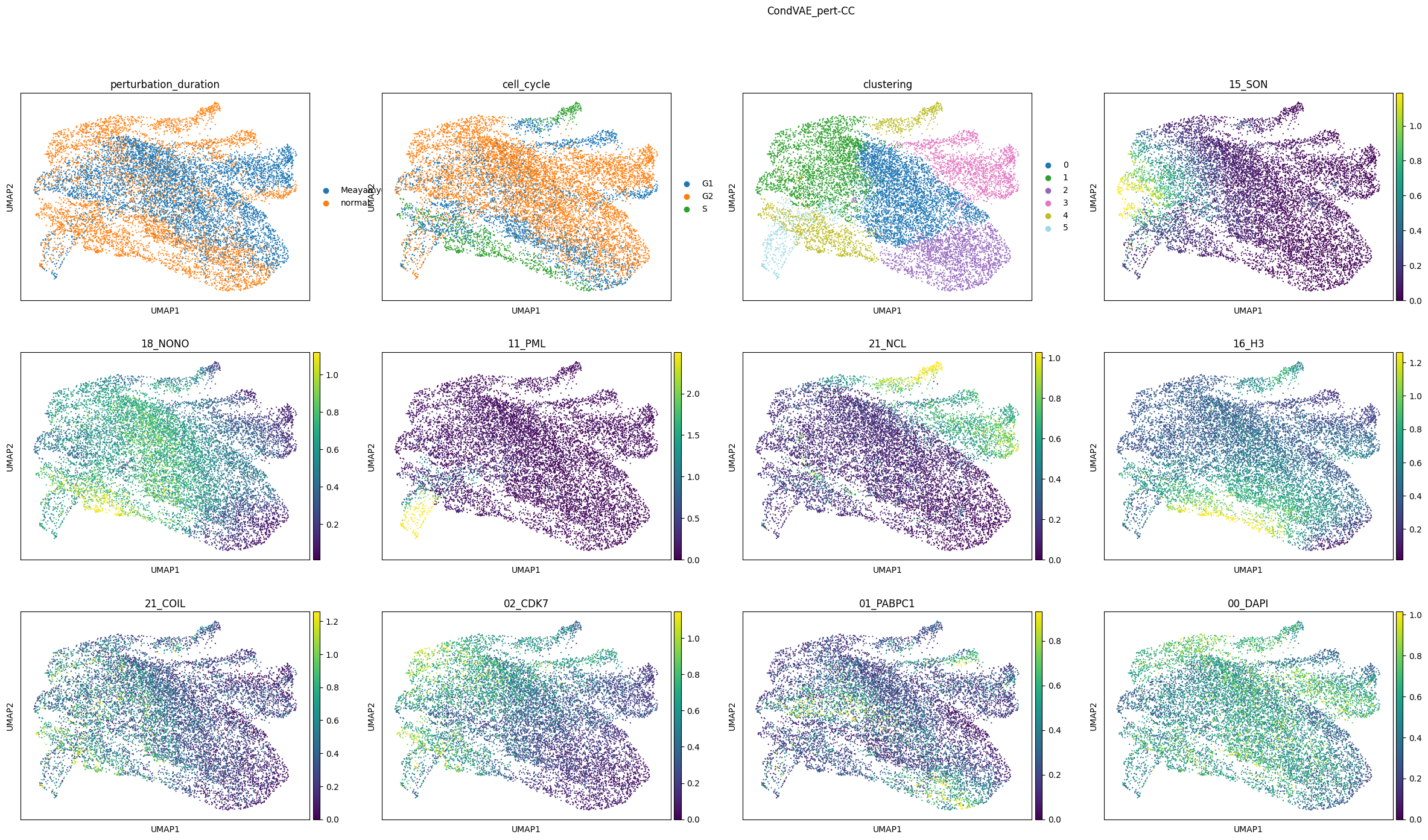
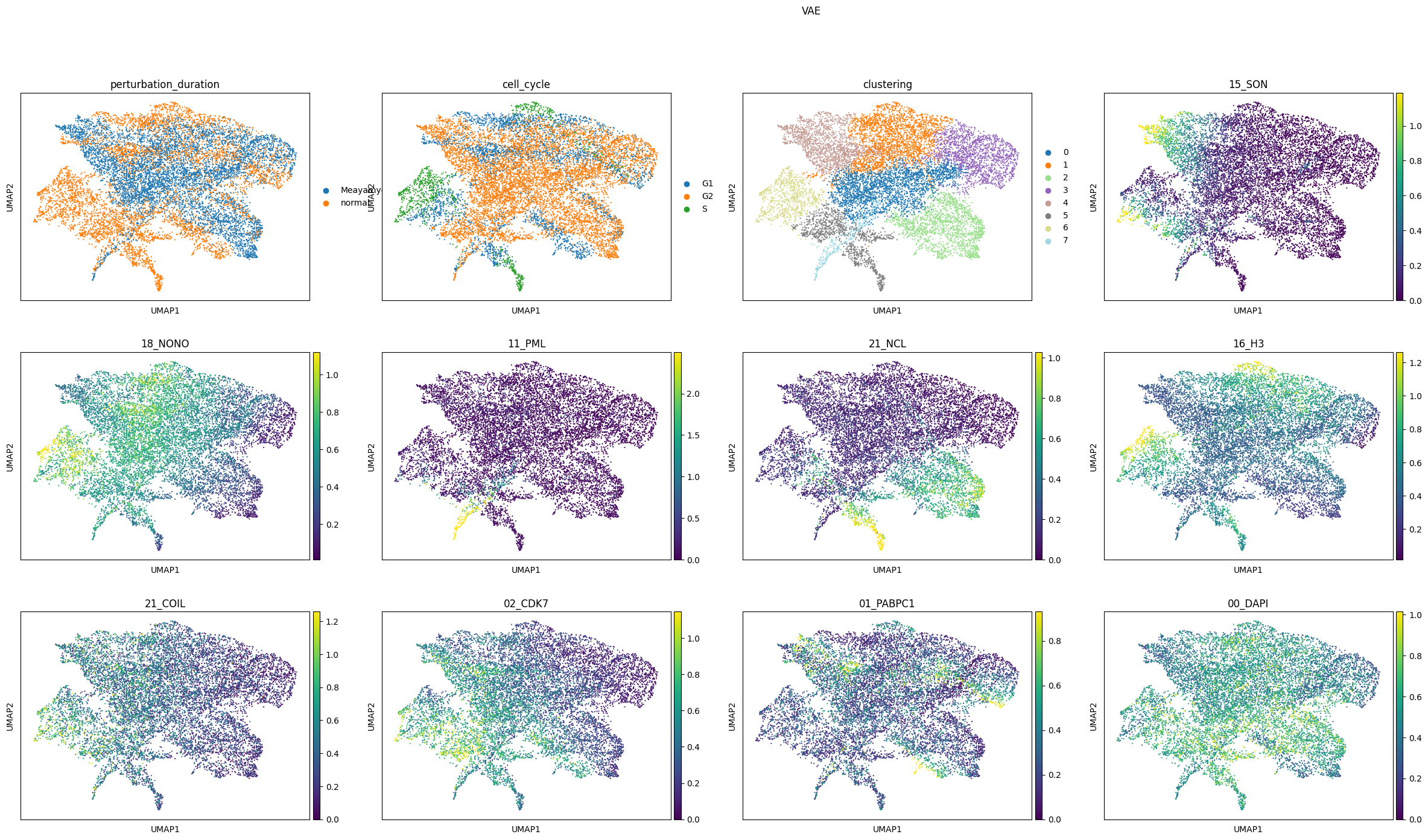
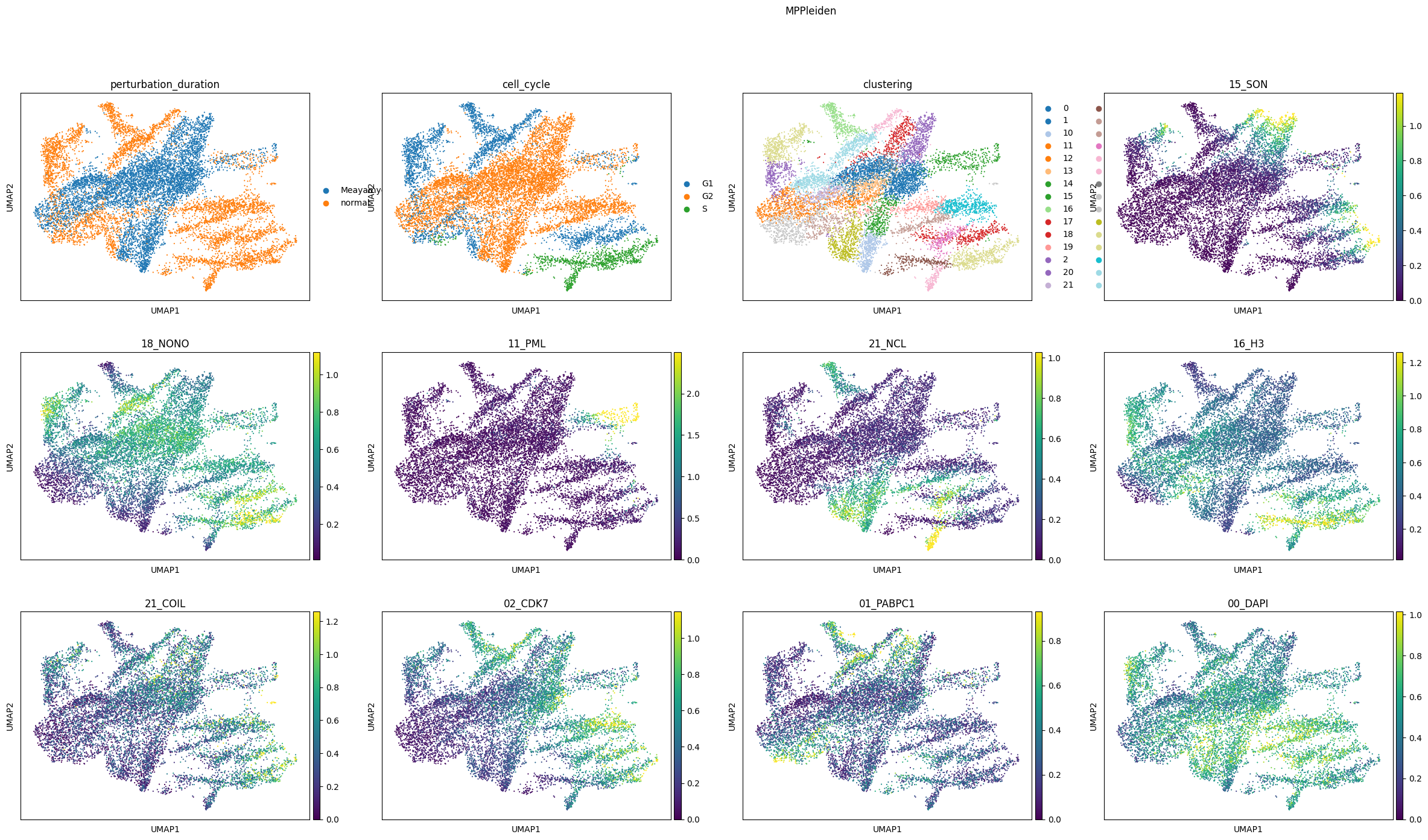
The pixel-level UMAP representations of the learned latent representations and the original molecular pixel profiles show that the condVAE_pert-CC model integrated the two perturbation best. In the two other UMAPs, several clusters are entirely only in one perturbation.
[21]:
comp.plot_umap(
channels=["15_SON", "18_NONO", "11_PML", "21_NCL", "16_H3", "21_COIL", "02_CDK7", "01_PABPC1", "00_DAPI"]
)
/home/icb/hannah.spitzer/miniconda3/envs/campa/lib/python3.9/site-packages/scanpy/plotting/_tools/scatterplots.py:392: UserWarning: No data for colormapping provided via 'c'. Parameters 'cmap' will be ignored
cax = scatter(
/home/icb/hannah.spitzer/miniconda3/envs/campa/lib/python3.9/site-packages/scanpy/plotting/_tools/scatterplots.py:392: UserWarning: No data for colormapping provided via 'c'. Parameters 'cmap' will be ignored
cax = scatter(
/home/icb/hannah.spitzer/miniconda3/envs/campa/lib/python3.9/site-packages/scanpy/plotting/_tools/scatterplots.py:392: UserWarning: No data for colormapping provided via 'c'. Parameters 'cmap' will be ignored
cax = scatter(
/home/icb/hannah.spitzer/miniconda3/envs/campa/lib/python3.9/site-packages/scanpy/plotting/_tools/scatterplots.py:392: UserWarning: No data for colormapping provided via 'c'. Parameters 'cmap' will be ignored
cax = scatter(
/home/icb/hannah.spitzer/miniconda3/envs/campa/lib/python3.9/site-packages/scanpy/plotting/_tools/scatterplots.py:392: UserWarning: No data for colormapping provided via 'c'. Parameters 'cmap' will be ignored
cax = scatter(
/home/icb/hannah.spitzer/miniconda3/envs/campa/lib/python3.9/site-packages/scanpy/plotting/_tools/scatterplots.py:392: UserWarning: No data for colormapping provided via 'c'. Parameters 'cmap' will be ignored
cax = scatter(
/home/icb/hannah.spitzer/miniconda3/envs/campa/lib/python3.9/site-packages/scanpy/plotting/_tools/scatterplots.py:392: UserWarning: No data for colormapping provided via 'c'. Parameters 'cmap' will be ignored
cax = scatter(
/home/icb/hannah.spitzer/miniconda3/envs/campa/lib/python3.9/site-packages/scanpy/plotting/_tools/scatterplots.py:392: UserWarning: No data for colormapping provided via 'c'. Parameters 'cmap' will be ignored
cax = scatter(
/home/icb/hannah.spitzer/miniconda3/envs/campa/lib/python3.9/site-packages/scanpy/plotting/_tools/scatterplots.py:392: UserWarning: No data for colormapping provided via 'c'. Parameters 'cmap' will be ignored
cax = scatter(